
问题
- String 是如何实现的?它有哪些重要的方法?
- JDK高版本中的String 有什么变化?
- 为什么 String 类型要用 final 修饰?
- == 和 equals 的区别是什么?
- String 和 StringBuilder、 StringBuffer 有什么区别
- String 的 intern() 方法有什么含义?
- String 类型在 JVM(Java 虚拟机)中是如何存储的?编译器对 String 做了哪些优化?
String的创建机理
由于String 使用过于频繁,Java为了避免在一个系统中产生大量的String对象, 引入了字符串常量池。其运行机制是:创建一个字符串时,首先检查池中是否有值相同的字
符串对象,如果有则不需要创建直接从池中刚查找到的对象引用;如果没有则新建字符串对 象,返回对象引用,并且将新创建的对象放入池中。但是,通过new方法创建的String对象是 不检查字符串池的,而是直接在堆区或栈区创建一个新的对象,也不会把对象放入池中。上 述原则只适用于通过直接量给String对象引用赋值的情况。
举例:String str1 = "123"; //通过直接量赋值方式,放入字符串常量池
String str2 = new String(“123”);//通过new方式赋值方式,不放入字符串常量池
注意:String提供了inter()方法。调用该方法时,如果常量池中包括了一个等于此String对象 的字符串(由equals方法确定),则返回池中的字符串。否则,将此String对象添加到池 中,并且返回此池中对象的引用。
全局常量池在每个VM中只有一份,存放的是字符串常量的引用值("123")*。class常量池是在编译的时候每个class都有的,在编译阶段,存放的是常量的符号引用。运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,也就是说,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。
String的特性
-
不可变:是指String对象一旦生成,则不能再对它进行改变。不可变的主要作用在于当一 个对象需要被多线程共享,并且访问频繁时,可以省略同步和锁等待的时间,从而大幅度提 高系统性能。不可变模式是一个可以提高多线程程序的性能,降低多线程程序复杂度的设计 模式。 -
针对常量池的优化:当2个String对象拥有相同的值时,他们只引用常量池中的同一个拷贝。当同一个字符串反复出现时,这个技术可以大幅度节省内存空间。
jdk8 和 jdk9 中的区别
jdk8 实现
//用于存储字符串的值
private final char value[];
//缓存字符串的hash code
private int hash; // Default to 0
...
jdk9 实现
//用于存储字符串的值
@Stable
private final byte[] value;
//编码标识符 LATIN1/UTF16
private final byte coder;
private int hash; // Default to 0
...
不再是char的数组了,改为byte数组 + coder。 我们都知道java中char是16位UTF16编码的,那么马上就会有个问题,byte数组是如何存下char数组的?
//参数为char[] 数组的构造函数
public String(char value[]) {
this(value, 0, value.length, null);
}
String(char[] value, int off, int len, Void sig) {
//<1> 如果传入的是char数组长度为0,那么创建空字符串的
if (len == 0) {
this.value = "".value;
this.coder = "".coder;
return;
}
//COMPACT_STRINGS 初始化值为true
if (COMPACT_STRINGS) {
//<2> 通过 StringUTF16.compress(value, off, len); 来判断,如果char数组存在 value > 0xFF 的值时,就返回null
byte[] val = StringUTF16.compress(value, off, len);
//
if (val != null) {
this.value = val;
this.coder = LATIN1;
return;
}
}
this.coder = UTF16;
//<3> 如果char数组存在 value > 0xFF那么将会把byte数组的长度改为两倍char数组的长度
this.value = StringUTF16.toBytes(value, off, len);
}
//StringUTF16.compress
public static byte[] compress(char[] val, int off, int len) {
byte[] ret = new byte[len];
if (compress(val, off, ret, 0, len) == len) {
return ret;
}
return null;
}
// compressedCopy char[] -> byte[]
@HotSpotIntrinsicCandidate
public static int compress(char[] src, int srcOff, byte[] dst, int dstOff, int len) {
for (int i = 0; i < len; i++) {
char c = src[srcOff];
//判断char的值是否大于 0xFF
if (c > 0xFF) {
len = 0;
break;
}
dst[dstOff] = (byte)c;
srcOff++;
dstOff++;
}
return len;
}
在上面<3> 中,如果构造函数传入的char[]数组有值大于0xFF(255)那么会直接走StringUTF16#toBytes方法,把原来char[]数组的长度扩大两倍
//StringUTF16#toBytes
public static byte[] toBytes(char[] value, int off, int len) {
//调用newBytesFor方法创建两倍长度的byte数组
byte[] val = newBytesFor(len);
for (int i = 0; i < len; i++) {
//用两个字节来填充数组
putChar(val, i, value[off]);
off++;
}
return val;
}
public static byte[] newBytesFor(int len) {
if (len < 0) {
throw new NegativeArraySizeException();
}
if (len > MAX_LENGTH) {
throw new OutOfMemoryError("UTF16 String size is " + len +
", should be less than " + MAX_LENGTH);
}
return new byte[len << 1];
}
static void putChar(byte[] val, int index, int c) {
assert index >= 0 && index < length(val) : "Trusted caller missed bounds check";
index <<= 1;
val[index++] = (byte)(c >> HI_BYTE_SHIFT);
val[index] = (byte)(c >> LO_BYTE_SHIFT);
}
jdk9 把char数组改为byte的意图也非常明显,char使用两个字节来存储一个字符。觉得都用不到0xFF之上的字符所以就改用了byte(byte一个字节),这样一来。如果没有使用到0xFF以上的字符,那么String占的内存能减少一倍,性能更高
接下来的一些方法解析都会基于jdk8
重要方法
StringBuffer 和 StringBuilder 为参数的构造函数
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
equals() 方法
public boolean equals(Object anObject) {
//<1> 对象引用相同直接返回true
if (this == anObject) {
return true;
}
//<2> 判断传入的是否是string类型,不是直接返回false
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
//把两个字符串都转换为 char 数组对比
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
//<3> 依次比较每一个字符 不相等就返回false
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
String类型重写了Object中的equals()方法,equals()方法需要传递一个Object类型的参数值,在比较时会先通过instanceof判断是否为String类型,如果不是直接返回false
//Object.equals
public boolean equals(Object obj) {
//比较引用是否相同 其实就是==
return (this == obj);
}
其他重要方法
indexOf():查询字符串首次出现的下标位置lastIndexOf():查询字符串最后出现的下标位置contains():查询字符串中是否包含另一个字符串toLowerCase():把字符串全部转换成小写toUpperCase():把字符串全部转换成大写length():查询字符串的长度trim():去掉字符串首尾空格replace():替换字符串中的某些字符split():把字符串分割并返回字符串数组join():把字符串数组转为字符串
与StringBuilder、StringBuffer 的区别
由于String是Final修饰的,所以在字符串拼接的时候如果使用String的话性能会很低(会重新生成一个新的String)所以提供了StringBuilder和StringBuffer来解决这个问题
类图
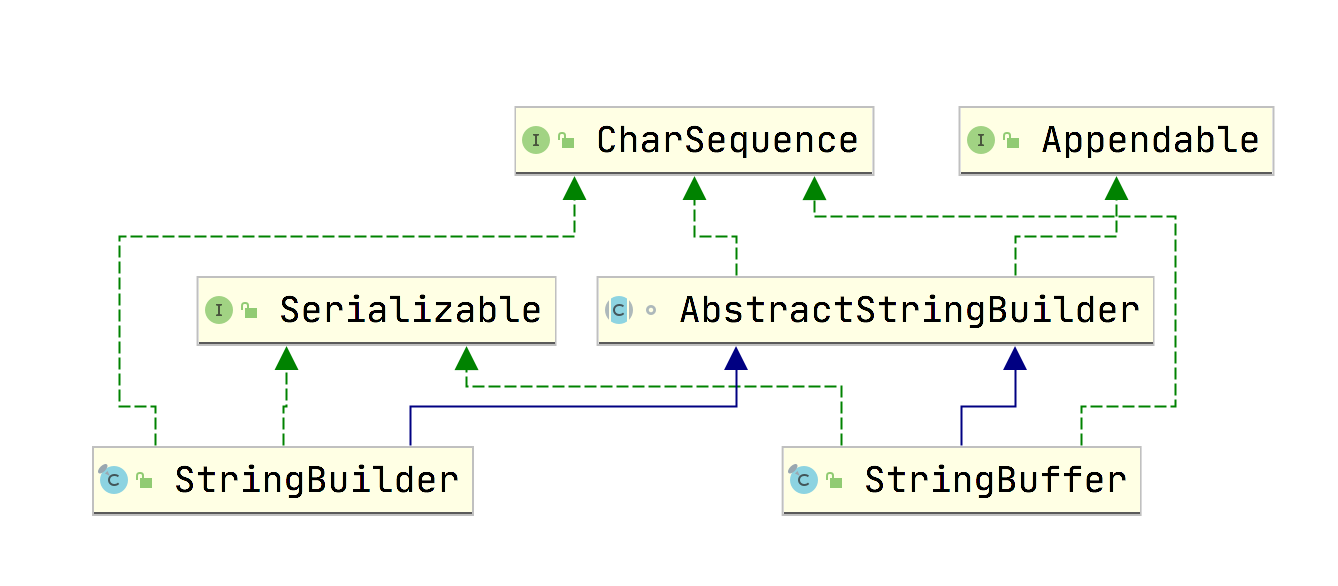 可以看到StringBuilder 和 StringBuffer 都继承于AbstractStringBuilder。
可以看到StringBuilder 和 StringBuffer 都继承于AbstractStringBuilder。
那我们就来看一下AbstractStringBuilder
AbstractStringBuilder
//用于存储字符串的值
char[] value;
//计数使用的字符数。
int count;
//append方法
public AbstractStringBuilder append(String str) {
if (str == null) {
return appendNull();
}
int len = str.length();
//判断是否需要扩容
ensureCapacityInternal(count + len);
//把str添加到char[]数组末尾
str.getChars(0, len, value, count);
count += len;
return this;
}
在jdk8中AbstractStringBuilder用于存储字符串值的是char[] value,和String同理,jdk9以上改用byte[]
StringBuilder
public StringBuilder append(String str) {
super.append(str);
return this;
}
StringBuffer
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
可以看到StringBuilder和StringBuffer都调用了 AbstractStringBuilder#append方法,唯一的区别在于StringBuffer加了synchronized锁来保证在多线程的情况下是线程安全的。
String因为是被final 修饰,所以也是线程安全的
String 与 JVM
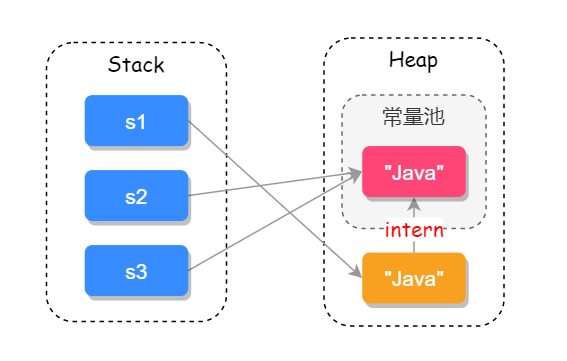
String 常见的创建方式有两种,直接赋值的方式“String s1 = "Java";”和“String s2 = new String("Java");”的方式,但两者在 JVM 的存储区域却截然不同,
在 JDK 1.8 中,变量 s1 会先去字符串常量池中找字符串 “Java”,如果有相同的字符则直接返回常量句柄,如果没有此字符串则会先在常量池中创建此字符串,然后再返回常量句柄;
而变量 s2 是直接在堆上创建一个变量,如果调用 intern 方法才会把此字符串保存到常量池中,如下代码所示:
String s1 = new String("Java");
String s2 = s1.intern();
String s3 = "Java";
System.out.println(s1 == s2); // false
System.out.println(s2 == s3); // false
它们在 JVM 存储的位置,如下图所示:
除此之外编译器还会对 String 字符串做一些优化,例如以下代码:
String s1 = "Ja" + "va";
String s2 = "Java";
System.out.println(s1 == s2); //true
我们使用javap来看一下反编译后的结果
Compiled from "StringExample.java"
public class com.test.StringExample {
public com.lagou.interview.StringExample();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String Java
2: astore_1
3: ldc #2 // String Java
5: astore_2
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: aload_1
10: aload_2
11: if_acmpne 18
14: iconst_1
15: goto 19
18: iconst_0
19: invokevirtual #4 // Method java/io/PrintStream.println:(Z)V
22: return
LineNumberTable:
line 5: 0
line 6: 3
line 7: 6
line 8: 22
}
从编译代码 #2 可以看出,代码 “Ja"+"va” 被直接编译成了 “Java” ,因此 s1==s2 的结果才是 true,这就是编译器对字符串优化的结果。
Strings4="Ja";
Strings5="va";
Strings6=s4+s5
s6反编译为(newStringBuilder()).append(s4).append(s5).toString(),s1在编译期为常量,s6被编译为StringBuilder及append,s6常量池只有Ja和va,这是s4和s5编译的,字符串拼接中,有一个参数是变量的话,整个拼接操作会被编译成StringBuilder.append,这种情况编译器是无法知道其确定值的,只有在运行期才能确定
总结
-
1. 在JDK1.8中,内部通过char数组作为存储结构
- 在构造器中能以String、char[]、StringBuffer、StringBuilder作为参数传入。
- equals() 比较两个字符串的值是否相等
-
2. JDK9之后String的存储结构从char数组转换成
byte[]数组,为了存储更加紧凑,占用的内存更少,操作性能更高 -
3. final 修饰的第一个好处是
安全;第二个好处是高效 -
4. ==对于基础类型来讲是比较
值是否相等;而对于引用类型来说,是用于比较引用地址是否相等;String#equals()方法是比较两个字符串的值是否相等 -
5. String类型是不可变的,所以在字符串拼接的时候如果使用String的话性能会很低(会重新生成一个新的String)
- StringBuffer:它提供了append和insert用于字符串拼接,使用 synchronized 来保证线程安全
- StringBuilder:它同样提供了append和insert的拼接方法,但它没有使用synchronized来修饰,因此在性能上要优于StringBuffer,并发场景下不安全。
-
6. 通过new String(“abc”) 创建的字符串会在堆上创建一个变量,如果调用
intern()方法才会把字符串保存到常量池中 -
7. String 类型在 JVM(Java 虚拟机)中的存储和对 String 做的优化,有以下这几种情况:
- String s1 = “Ja” + “va”;编译期 被jvm优化编译为
java常量池不存在就创建。 - String s2 = “Java”;编译期 常量池不存在就创建。
- String s3 = new String(“java”);常量池的"java"在编译期确认,类加载的时候创建(常量池不存在时);堆中的"java"是在运行时确定,在new时创建。
- Strings4="Ja”;Strings5="va”;Strings6=s4+s5;s6反编译为(newStringBuilder()).append(s4).append(s5).toString(),s1在编译期为常量,s6被编译为StringBuilder及append,s6常量池只有Ja和va,这是s4和s5编译的,字符串拼接中,有一个参数是变量的话,整个拼接操作会被编译成StringBuilder.append,这种情况编译器是无法知道其确定值的,只有在运行期才能确定
- String s7 = (s4 + s5).intern();把字符串字面量放入常量池(不存在的话),返回这个常量的引用。
- String s1 = “Ja” + “va”;编译期 被jvm优化编译为