
简介
操作系统为了方便用户使用对硬件进行抽象,屏蔽各种细节的处理,而JMM(Java内存模型)是在硬件内存模型上的更高层的抽象,它屏蔽了各种硬件和操作系统访问的差异性,保证了Java程序在各种平台下对内存的访问都能达到一致的效果。
在并发编程中,需要处理两个关键问题:线程之间如何通信及线程之间如何同步。
通信是指线程之间以何种机制来交换信息,线程之间的通信机制有两种:共享内存和消息传递。同步是指程序中用于控制不同线程间操作发生相对顺序的机制- 在
共享内存并发模型里,同步是显式进行的。必须显式指定某个方法或某段代码需要在线程之间互斥执行。 - 在
消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
- 在
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程完全透明。如果编写多线程程序的Java程序员不理解隐式进行的线程之间通信的工作 机制,很可能会遇到各种奇怪的内存可见性问题。
在Java的内存模型之前,先了解一下硬件层面的内存模型:
硬件内存模型
在现代计算机的硬件体系中,CPU的运算速度是非常快的,远远高于它从存储介质读取数据的速度,这里的存储介质有很多,比如磁盘、光盘、网卡、内存等,这些存储介质有一个很明显的特点——距离CPU越近的存储介质往往越小越贵越快,距离CPU越远的存储介质往往越大越便宜越慢。
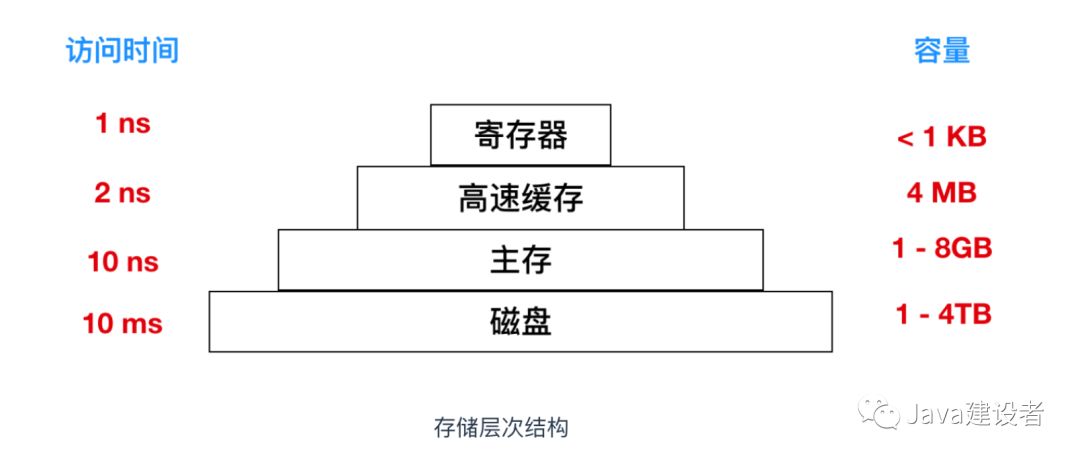 上图
上图分层存储器体系(memory hierarchy)中,位于顶层的存储器速度最快,但是相对容量最小,成本非常高。层级结构向下,其访问速度会变慢,但是容量会变大,相对造价也就越便宜
所以,在程序运行的过程中,CPU大部分时间都浪费在了磁盘IO、网络通讯、数据库访问上,如果不想让CPU在那里白白等待,我们就必须想办法去把CPU的运算能力压榨出来,否则就会造成很大的浪费,而让CPU同时去处理多项任务则是最容易想到的,也是被证明非常有效的压榨手段,这也就是我们常说的“并发执行”。
但是,让CPU并发地执行多项任务并不是那么容易实现的事,因为所有的运算都不可能只依靠CPU的计算就能完成,往往还需要跟内存进行交互,如读取运算数据、存储运算结果等。
前面我们也说过了,CPU与内存的交互往往是很慢的,所以这就要求我们要想办法在CPU和内存之间建立一种连接,使它们达到一种平衡,让运算能快速地进行,而这种连接就是我们常说的“高速缓存”。
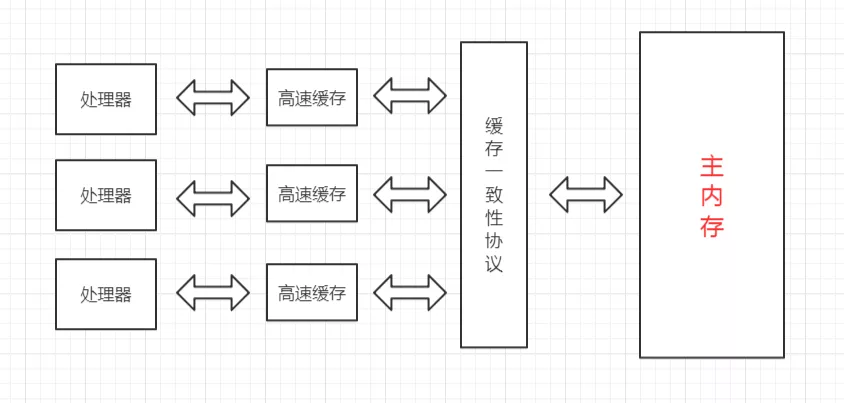
高速缓存的速度是非常接近CPU的,但是它的引入又带来了新的问题,现代的CPU往往是有多个核心的,每个核心都有自己的缓存,而多个核心之间是不存在时间片的竞争的,它们可以并行地执行,那么,怎么保证这些缓存与主内存中的数据的一致性就成为了一个难题。
为了解决缓存一致性的问题,多个核心在访问缓存时要遵循一些协议,在读写操作时根据协议来操作,这些协议有MSI、MESI、MOSI等,它们定义了何时应该访问缓存中的数据、何时应该让缓存失效、何时应该访问主内存中的数据等基本原则。
 而随着CPU能力的不断提升,
而随着CPU能力的不断提升,一层缓存就无法满足要求了,就逐渐衍生出了多级缓存。
按照数据读取顺序和CPU的紧密程度,CPU的缓存可以分为一级缓存(L1)、二级缓存(L2)、三级缓存(L3),每一级缓存存储的数据都是下一级的一部分。
这三种缓存的技术难度和制作成本是相对递减的,容量也是相对递增的。
所以,在有了多级缓存后,程序的运行就变成了:
- 当CPU要读取一个数据的时候,先从一级缓存中查找,如果没找到再从二级缓存中查找,如果没找到再从三级缓存中查找,如果没找到再从主内存中查找,然后再把找到的数据依次加载到多级缓存中,下次再使用相关的数据直接从缓存中查找即可。
- 而加载到缓存中的数据也不是说用到哪个就加载哪个,而是加载内存中连续的数据,一般来说是加载连续的64个字节,因此,如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个元素也会被加载到缓存中,这就是“
缓存行”的概念。
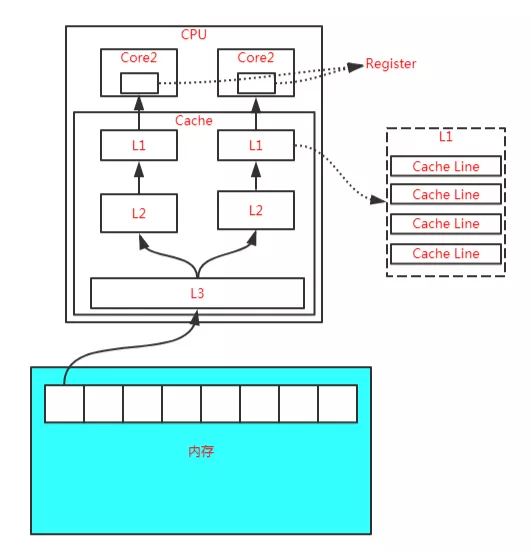
缓存行虽然能极大地提高程序运行的效率,但是在多线程对共享变量的访问过程中又带来了新的问题,也就是非常著名的“伪共享”。
除此之外,为了使CPU中的运算单元能够充分地被利用,CPU可能会对输入的代码进行乱序执行优化,然后在计算之后再将乱序执行的结果进行重组,保证该结果与顺序执行的结果一致,但并不保证程序中各个语句计算的先后顺序与代码的输入顺序一致,因此,如果一个计算任务依赖于另一个计算任务的结果,那么其顺序性并不能靠代码的先后顺序来保证。
与CPU的乱序执行优化类似,java虚拟机的即时编译器也有类似的指令重排序优化。
为了解决上面提到的多个缓存读写一致性以及乱序排序优化的问题,这就有了内存模型,它定义了共享内存系统中多线程读写操作行为的规范。
Java内存模型
Java内存模型(Java Memory Model,JMM)是在硬件内存模型基础上更高层的抽象,它屏蔽了各种硬件和操作系统对内存访问的差异性,从而实现让Java程序在各种平台下都能达到一致的并发效果。
JMM 定义了线程和主内存的抽象关系:
- 线程之间的
共享变量存储在主内存之中- 共享变量:堆内存在线程之间共享,存储在堆内存中所有实例域、静态域和数组元素都是共享变量
- 每个线程都有一个私有的
本地内存,本地内存中存储了该线程用以读/写共享变量的副本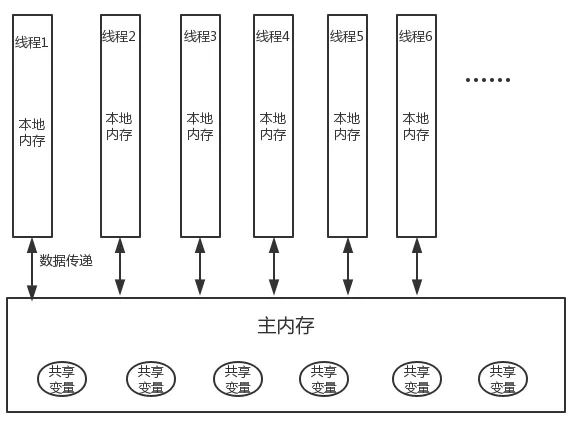
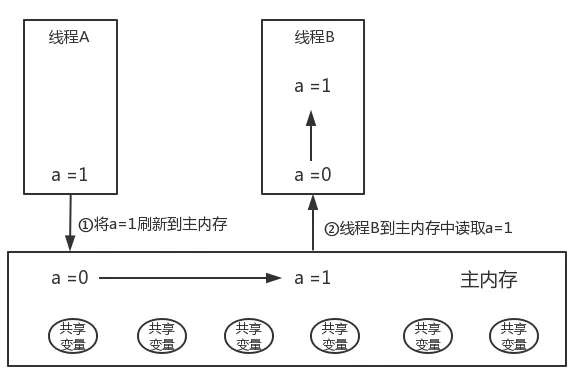
线程之间通信
线程A 与 线程B 之间通信:
- 线程A把本地内存A中的共享变量
刷新到主内存中去。 - 线程B到主内存中去
读取线程A之前已更新过的共享变量。
从整体来看,这个过程就是线程A在向线程B发送消息。这个通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为Java程序员提供内存可见性保证。
重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。
从 Java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

-
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。 -
指令级并行的重排序。处理器将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。 -
内存系统的重排序。处理器使用缓存和读/写缓冲区,使得加载和存储操作看上去可能是在乱序执行。
举例:如下代码执行过程中,程序不一定按照先A后B的顺序执行,经重排序之后可能按照先B后A的顺序执行。
int a = 1;// A
int b = 2;// B
虽然重排序是为了提高性能,但是也要遵守一定的规则:
-
数据依赖性:如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这就存在数据两个操作之间依赖性。 -
as-if-serial 语义:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。
重排序的问题
重排序可以提高程序执行的性能,但是代码的执行顺序改变,依靠as-if-serial 语义在单线程中没有问题,但是多线程程序可能会出现可见性问题和有序性问题。
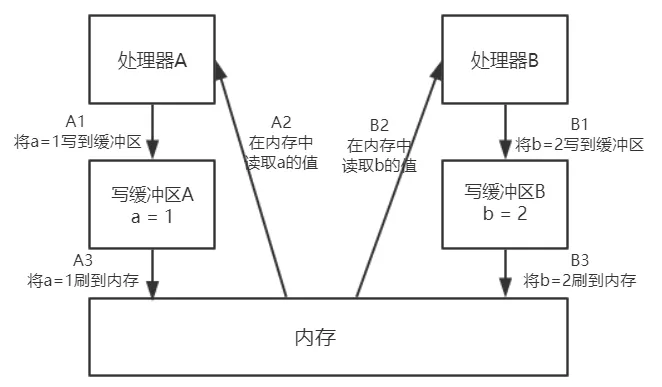
举例:
初始状态:a = b = 0;x = y = 0;
Processor A:
a = 1; // A1
x = b; // A2
Processor B:
b = 2; // B1
y = a; // B2
如上代码,Processor A和Processor B同时执行,最终却可能得到x = y = 0的结果。
原因分析:
-
第一步执行A1/B1将
a=1/b=2写到缓冲区,此时写缓冲区还在等待其他写操作,不执行A3,所以内存中的a=0; -
第二步执行A2/B2,处理器读取内存中的a,得到
a=0; -
虽然处理器 A 执行内存操作的顺序为:A1->A2,但内存操作实际发生的顺序却是:A2->A1。此时,
处理器 A 的内存操作顺序被重排序了。
解决重排序
1)对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。
2)对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,来禁止特定类型的处理器重排序。
3)JMM根据代码中的关键字(如:synchronized、volatile)和J.U.C包下的一些具体类来插入内存屏障。
JMM 把内存屏障指令分为下列四类:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1; LoadLoad;Load2 | 确保Load1数据的装载,之前于Load2及所有后续装载指令的装载 |
| StoreStore Barriers | Store1; StoreStore;Store2 | 确保Store1数据对其他处理器可以(刷新到内存),之前于Store2 以所有后续存储指令的存储 |
| LoadStore Barriers | Load1; LoadStore;Store2 | 确保Load1数据装载,之前于Store2及所有后续的存储指令刷新到内存 |
| StoreLoad Barriers | Store1; StoreLoad;Load2 | 确保Store1数据对其他处理器可以(刷新到内存),之前于Load2及所有后续装载指令的装载 |
happens-before
如果Java内存模型的有序性都只依靠volatile和synchronized来完成,那么有一些操作就会变得很啰嗦。
JMM提供了简单易懂的happens-before原则,并向程序员保证执行并发程序会遵守happens-before原则。按照happens-before原则写并发代码,就能保证内存可见性和有序性。
happens-before规则:
-
程序次序规则:一个线程内,按照代码顺序,写在前面的操作先行发生于写在后面的操作; -
锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作; -
volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作; -
传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C; -
线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作; -
线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生; -
线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过 Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行; -
对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
总结
- 为了提高性能,编译器和处理器常常会对指令做重排序。三种重排序:编译器优化的重排序、指令级并行的重排序、内存系统的重排序。
- as-if-serial语义要求:不管怎么重排序,单线程程序的执行结果不能被改变。
- JMM编译时在当位置会插入内存屏障指令来禁止特定类型的重排序
- happens-before原则:程序次序原则、监视器锁定原则、volatile原则、线程启动原则、线程终止原则、线程中断原则、对象终结原则、传递性原则;
参考
《Java 并发编程实战》
《Java 并发编程的艺术》
The Java® Virtual Machine Specification -> Threads and Locks