
Data Flow
Pulsar 集群
1. Brokers + Bookies
前边我们提到过,broker 是各零件之间进行交换的对象。因 Pulsar 为分层架构模式,使用了 BookKeeper 作为额外的存储系统,bookies 就是 BookKeeper 里的存储节点。 Brokers+Bookies 构成 Pulsar 的两个层次,共同完成了 Pulsar 的数据服务。
Broker:整个消息层的生产和消费,无存储状态
Bookie:数据持久化保存的节点,有存储状态
2. ZooKeeper
ZooKeeper 在 Pulsar 里的作用是存储 Pulsar 系统里元数据的存储和集群的管理以及节点的发现等,节点发现是指发现集群里有多少个 broker,有多少 bookie。 ZooKeeper 作为元数据系统,有好有坏,当然 Pulsar 也不会完全依赖于 ZooKeeper,目前 Pulsar 有很好的元数据抽象,你可以把 ZooKeeper 换为其他的强一致系统,比如 ETCD。
以上这三个组件,构成了 Pulsar 的集群。Brokers+bookies 为数据服务,ZooKeeper 为元数据服务。
数据流动的过程
Producer 通过生产消息到一个topic,一个topic中可能有N个 partition,每个 partition 给一个 broker 服务;那 consumer 会根据要消费的 topic 以及具体的 partition找到所服务的 broker 并进行消费
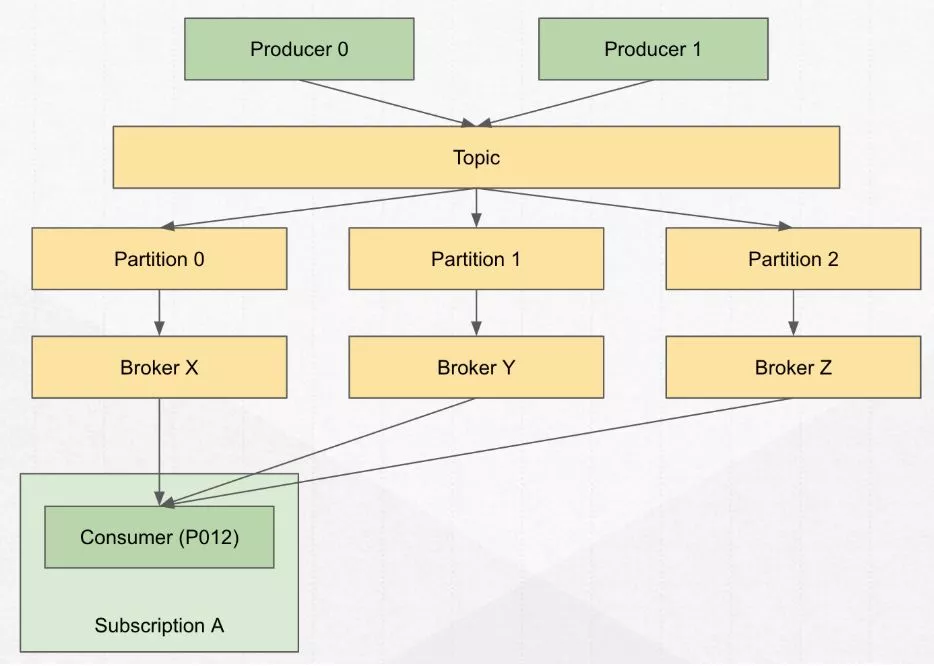
1.写过程(Producer -> Broker)
首先客户端会调用 Pulsar 提供给客户端的 API,这就是 producer。创建消息后,可以放进 pillow 里,也可以指定 key,放在一条消息里面,这条消息通过应用客户端传给 producer。
生产端的内部有一个叫 MessageWriter 的类,这个 MessageWriter 默认是 round-robin 的过程,相当于每发一条消息会轮询的去找一个 partition 去发送,为了提高效率,在一定的时间内只会选择一个 producer。
有时你会给 message 指定 key ,一旦指定它会根据 key 的 hash 去找出相应的 partition,如果你觉得 Pulsar 提供的 MessageWriter 不是很好,也可以自定义 MessageWriter。
这些操作对应下图中的1.
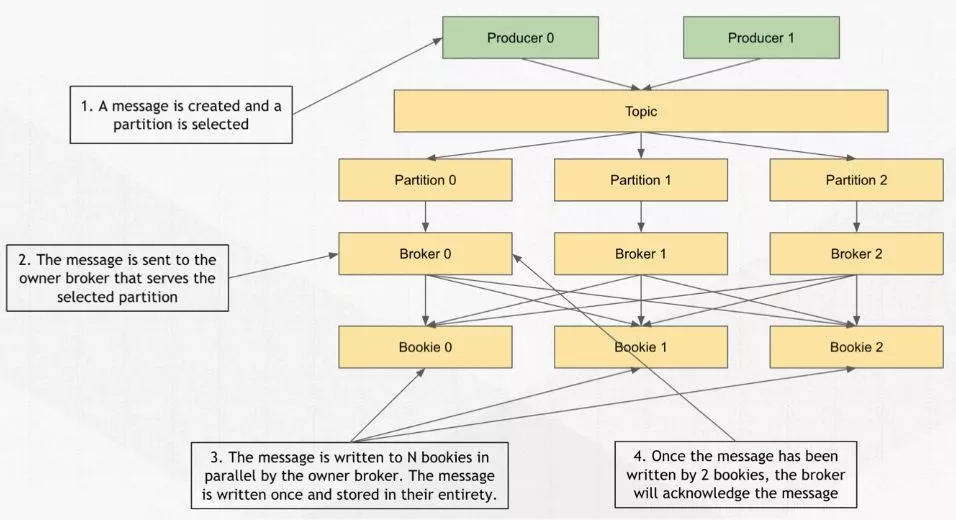 一旦partition被选出来,客户端会跟 broker 打交到,找出这个partition 究竟在哪个broker上,这个寻找过程就是
一旦partition被选出来,客户端会跟 broker 打交到,找出这个partition 究竟在哪个broker上,这个寻找过程就是 Topic Discovery。Broker 收到消息后会调用 Bookkeeper的客户端并发的去写多个副本。对应上图中的2.
整个并发写的流程是被封装到 BookKeeper 的客户端中,所以可以认为是 broker 调用 BookKeeper 的客户端去写 bookies,当 broker 收到了两个副本的 ACK 之后它会认为这条消息已经写成功,broker 会返回客户端,告知这条消息已经被持久化完成。对应上图中的3.4.
整个写的过程消息是从 producer 写到 broker,然后经过 broker 到 BookKeeper 上。整个过程中客户端都不会跟 ZooKeeper 打交道,你也不会跟 BookKeeper 打交道,唯一打交道的只有 broker。
2.读过程(Broker -> Consumer)
当 consumer 去Broker中读取消息的时候,会有两种情况。
a.Broker 已经缓存了消息
Broker 可能已经缓存了部分消息,这时 consumer 在订阅某个 topic 时根据订阅的策略来消费哪几个 partition ,比如 Failover 订阅是消费其中的某一个 partition,这时它同样会经过 Topic Discovery 的过程,找到 consumer 要连接的 broker 。
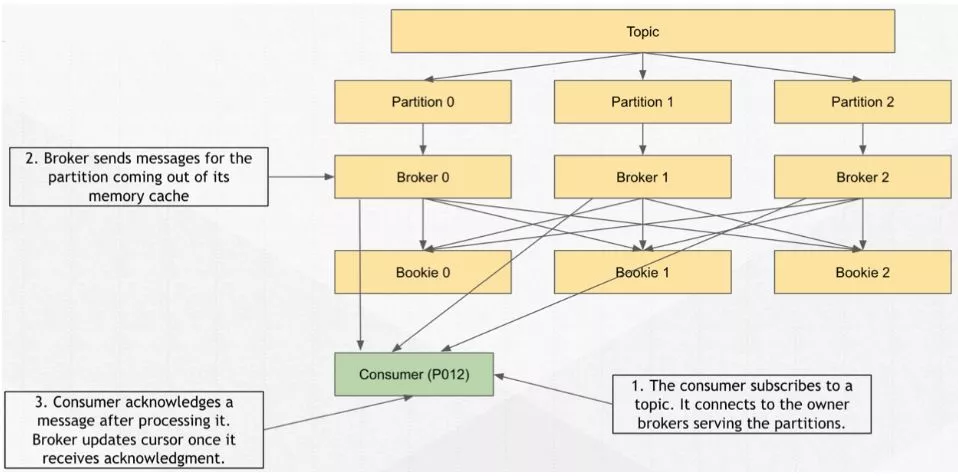 Consumer 在连接到 broker 后建立长连接,这些消息完全存到 bookie 后,从内存里拿出来通过
Consumer 在连接到 broker 后建立长连接,这些消息完全存到 bookie 后,从内存里拿出来通过推得方式 dispatch 给 consumer,consumer 收到消息后会放到消费端的 receiver queue ,之后应用端可以去 receiver queue 消费数据,消费完成后,consumer 会重新发起一个 flow request。
b.Broker 没有缓存消息
上边这种方式整个延迟是比较短的,但如果需要做回滚消费的操作,这时候 broker 已经不再缓存这部分数据,而去从 bookie 去读数据,数据读出后再 dispatch 给 consumer,这个读取过程可以选择任意一个存储节点去读消息。
整个存储架构没有主节点的说法,可以避免某个节点由于网络或者性能导致的高延迟读取,这也是分层存储带来的好处。那 broker 如何从 bookie 中读消息呢?其实是在 BookKeeper Client 中完成。
3.Failure Handing(故障处理)
a. Producer 端产生 failure
当出现「发消息网络断开、broker crash」等情况时,这个时候 producer 有 pending queue ,会在设置的 timeout 期间内对断开网络的连接进行重试。
b. Broker 端产生 failure
因为 broker 是没有状态的,所以它不保存任何数据,一旦 crash 后,topic 的 ownership 会被其他的 broker 掌管,这时候你的服务可以快速被恢复。
c. 存储节点产生 failure
存储节点只管理存储,如果只挂掉一个 bookie ,broker 是不会被感知的,除非所有的 bookie 都挂掉,没有足够的副本数量去写入数据。
正常情况下挂掉一两台节点,broker 会感知到然后新开一个 segment 到其他 bookie 上写入数据,因此 broker 挂掉不会影响数据的写入,也不会影响读取。
d. Consumer 端产生 failure
当 broker 挂掉,直到整个 TCP 断开,然后会重连到新的 broker 上去。
所以,Data Flow 总的来说就三大块:Producer、Broker、Consumer。Broker 与生产者和消费者联系沟通,Bookie 与 broker 进行沟通相连,以此来完成从生产端到消费端的处理。
Data Retention
消费者连接订阅时,如果这个订阅原来不在 Pulsar 系统里存在,那么应如何创建 cursor 呢。这里就出现了两个概念:
Earliest /Latest。
Earliest:如果订阅对应的游标不存在,如果你在连接接消费者订阅时,指定 earliest,它会放到整个流的有效数据第一条(最早的数据)。
Latest:链接消费者订阅时,指定 latest,它会放到整个流的有效数据最末端。
默认行为是 latest,与 Kafka 的默认行为(类似于 earliest)是有区别的
Cursor 放置的位置,决定了你最终消费了什么数据。
Unsubscribe
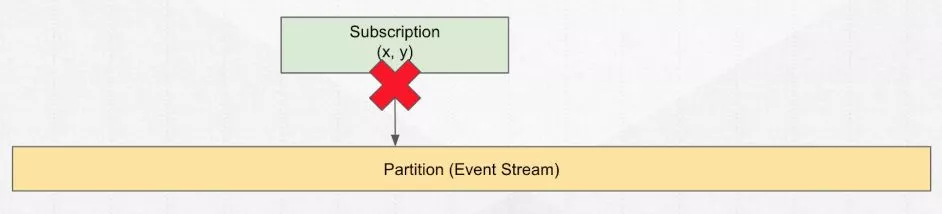 一旦消费完毕,你不需要这些消息了,需要进行
一旦消费完毕,你不需要这些消息了,需要进行 unsubcribe,将 cursor 从这个流里拿掉,这样才能做到数据的完全清除。因为 cursor 不处理掉的话,这部分数据是会被保留下来的。
Message Retention
Pulsar 是基于
订阅的消息系统,一旦有订阅存在,订阅以后的所有消息都是需要被保留的,不能删除。
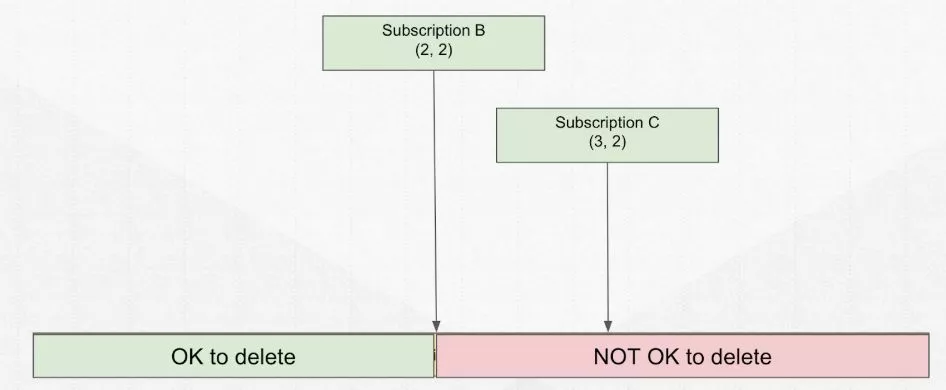
消费位置最早的订阅决定了你能保留消息多久。订阅之前的消息可被删除,这是 Pulsar 的默认行为,即消费完就可以被删除,释放空间留给之后的消息使用。
由于流计算的需求,有些数据消费完还不能删除,需要再额外保留个三五天。这种情况下,就需要有 retention 来进行数据保留设置。
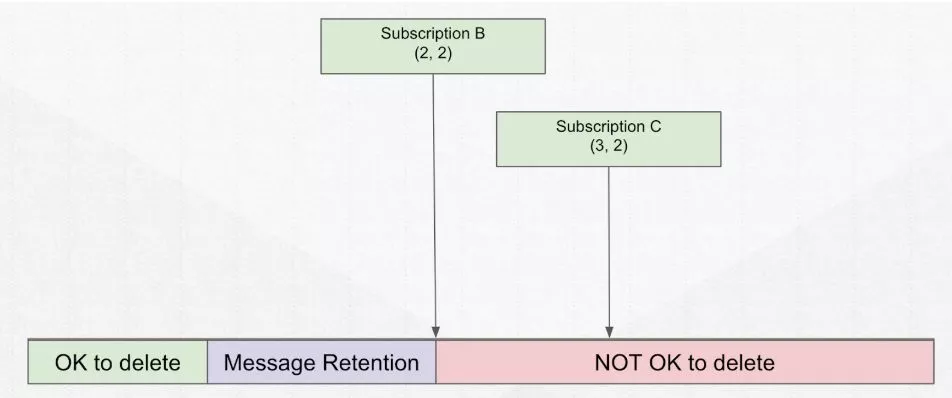 添加 retention 后,该部分数据可以保留多大内存/多少天,应用在紫色区域的数据。前提是你的数据已被所有的
添加 retention 后,该部分数据可以保留多大内存/多少天,应用在紫色区域的数据。前提是你的数据已被所有的 subscription 消费完毕,retention 设置才可以生效。
TTL
 由于后边未开始被消费的订阅还没有处理完全,所以仍需要进行操作。这些未处理消息没有被删除,但是所有的 consumer 均已下线,那么消息是永远不会被确认的。这样消息就会被一直累积。
由于后边未开始被消费的订阅还没有处理完全,所以仍需要进行操作。这些未处理消息没有被删除,但是所有的 consumer 均已下线,那么消息是永远不会被确认的。这样消息就会被一直累积。
 为了保证整个生产线的正常运作,可以在这些「
为了保证整个生产线的正常运作,可以在这些「橘色消息」部分添加 TTL。TTL 作用范围是没被确认/消费的消息,通过移动 cursor 来实现确认目标。
TTL 的好处在于,可以保证消息的过期时间与 retention 的过期时间保持一致。一旦消息自动过期,会进入 retention 的处理流程,然后再利用 TTL 的特性进行数据清除。
补充概念:Message backlog 是指还没有被处理/消费的部分消息。Topic level 下的 backlog 是整个 topic 下最大的 backlog。
Message Deletion
 正常情况下,消息过期就会被删除,比如上图的 5-9 就会被删除。但事实 Pulsar 并不会这么处理。
正常情况下,消息过期就会被删除,比如上图的 5-9 就会被删除。但事实 Pulsar 并不会这么处理。
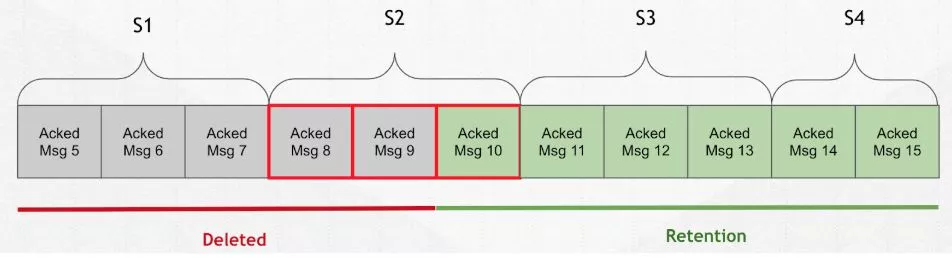 由于 Pulsar 的分片架构模式,所以删除的行为不是「按个进行」,而是「按片进行」。上图中 S2 部分,
由于 Pulsar 的分片架构模式,所以删除的行为不是「按个进行」,而是「按片进行」。上图中 S2 部分,有部分数据是已经过期需要删除的。在 Pulsar 的实际处理过程中,是不把 Msg 8和9 进行过期处理的,它会根据 S1-S2 之间的间隔进行过期分离然后处理掉。
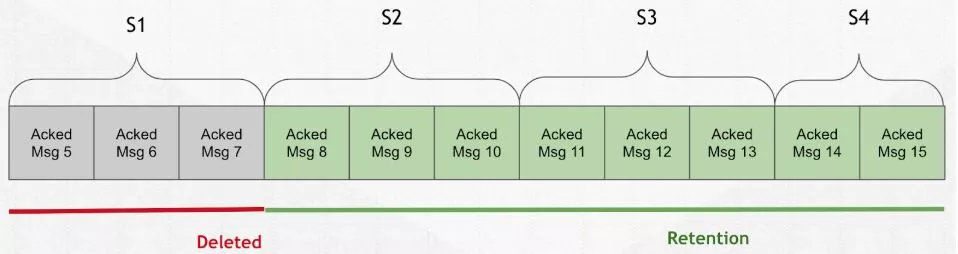 所以真正意义上的 retention 是遵循了分片结构的模式,即 8、9、10 仍会被
所以真正意义上的 retention 是遵循了分片结构的模式,即 8、9、10 仍会被保留。
Storage Size
Storage size 是计算所有没被删除的 segment 所占用的存储空间。所以跟上文提到的 Pulsar message deletion 一样,需要整个分片都被填满后/周期滚动,旧的 segment 才会被删除。
所以整个存储空间是按 segment 之间的存储力度进行计算的,同时 garbage collector 是在后台定期执行的,比如 1 小时/15 天。所以这就是为什么有时你发现 segment 已经被拿掉,但是 storage size 依旧没有变化的原因
本文参考自Pulsar社区,如果对Pulsar感兴趣,可通过下列方式参与Pulsar社区:
-
Pulsar Slack频道: https://apache-pulsar.slack.com/
可自行在这里注册: https://apache-pulsar.herokuapp.com/
-
Pulsar邮件列表: http://pulsar.incubator.apache.org/contact
有关Apache Pulsar项目的常规信息,请访问官网: http://pulsar.incubator.apache.org/ 此外也可关注Twitter帐号@apache_pulsar。